이 글은 전공 수업 내용을 복습할 겸 기록해놓은 글입니다.
추가할 사항이 있거나 잘못된 점이 있으면 댓글로 남겨주세요.
반정규화(Denormalization)
- 정규화된 엔티티, 속성, 관계에 대해 성능 향상을 위해 중복, 통합, 분리를 수행하는 데이터 모델링 기법
정규화를 수행하지 않은 것(비정규화)이 아님. - 특징
테이블, 칼럼, 관계의 반정규화를 종합적으로 고려
- 일반적으로 Column의 중복을 통해 수행
과도한 반정규화는 데이터의 무결성을 침해 - 반정규화 절차
반정규화 대상조사
- 전체 데이터의 양을 조사하고 그 데이터가 해당 프로세스를 처리할 때 성능저하가 나타나는지 검증
다른 방법 유도 검토
- 데이터를 중복해 데이터 무결성을 깨뜨릴 위험을 제어하기 위해 먼저 다른 방법을 모색
- 뷰 테이블 : 뷰 자체는 성능 향상을 가져오지는 않지만, 신중하게 설계된 뷰를 재사용 사용하면 성능 향상
- 클러스터링 : 자주 사용되는 테이블의 데이터를 디스크와 같은 블록에 저장
- 인덱스 조정 : 인덱스 추가, 삭제 및 순서 조정
- 응용 어플리케이션 : 데이터 처리를 위한 로직 변경
반정규화 적용
- 성능에 대한 고려가 충분히 이루어져서 반정규화를 적용해야한다는 판단이 들 때 반정규화 적용

반정규화 기법
- 칼럼 반정규화
중복칼럼 추가
- 해당 테이블에서 자주 사용하는 칼럼을 중복시킴
파생칼럼 추가
- 질의가 예상되는 값을 미리 계산하여 저장
이력테이블칼럼 추가
- 이력 테이블에 최근값, 종료여부 등의 칼럼을 중복으로 추가
PK의 의미적 분리를 위한 칼럼 추가
- PK가 복합 의미를 갖는 경우 구성 요소 값의 조회 성능 향상을 위해 일반 속성 추가
데이터 복구를 위한 칼럼 추가
- 사용자의 실수 또는 응용 프로그램 오류로 인해 데이터가 잘못 처리된 경우
- 원래 값으로의 복구를 위해 이전 데이터를 임시로 중복 저장

- 테이블 반정규화
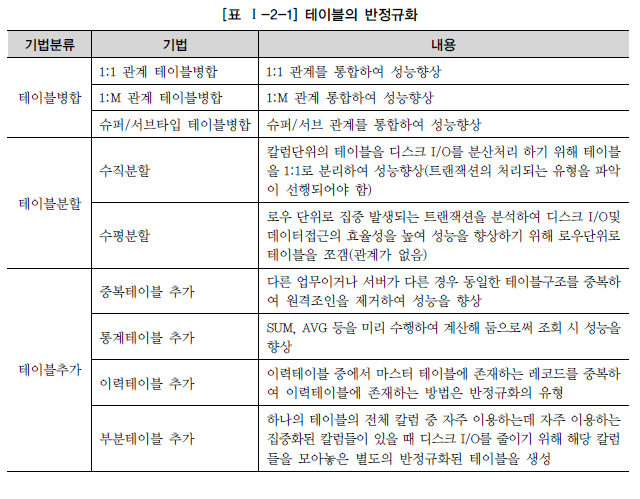
테이블병합
관계 병합
- 두 테이블의 동시 조회가 많은 경우 수행
슈퍼/서브타입 병합
- 일반화 관계 표현
- 여러 엔티티의 공통 속성을 Super Type, 개별 속성을 Sub Type으로 구성
- 데이터의 양과 트랜잭션의 유형에 따라 테이블 구조 결정
- 개별 접근 트랜잭션이 많으면 One to One type (개별 테이블 유지)
- 슈퍼타입 + 서브타입 접근 트랜잭션이 많으면 Plus Type (슈퍼 + 서브타입 테이블)
- 여러 서브타입에 대한 동시 접근이 많으면 Single Type (하나의 통합 테이블)
테이블분할
수직분할
- 많은 칼럼을 가진 테이블에서 프로세스가 칼럼 유형마다 다르게 발생하는 경우 수행
수평 분할
- 테이블이 많은 양의 데이터를 가질 것으로 예상되는 경우 수행
- Range Partitioning : 범위 분할 (범위, 숫자)
- List Partitioning : 값 분할 (값)
- Hash Partitioning : 해시 함수로 분할
테이블추가
이력테이블 추가
- 가장 최근 값을 중복으로 기록한 테이블 생성
부분 테이블 추가
- 집중적으로 자주 사용되는 특정 속성들을 추출해 별도 테이블 구성
- 테이블 수직 분할과 달리 원본 테이블은 유지
중복 테이블 추가
- 원격 조인을 제거하기 위해 동일한 테이블 구조를 중복
통계 테이블 추가
- 통계값을 미리 계산해 저장
- 관계 반정규화
중복관계 추가
- 조인을 통해 정보 조회가 가능하지만, 조인 경로 단축을 위해 중복관계 추가
'데이터베이스(Database) > Data Modeling' 카테고리의 다른 글
| [DB] 데이터 모델링(10) - 분산 데이터베이스 (0) | 2022.10.24 |
|---|---|
| [DB] 데이터 모델링(8) - 정규화(Normalization) (0) | 2022.10.24 |
| [DB] 데이터 모델링(7) - 성능 데이터 모델링과 관계형 모델 (0) | 2022.10.24 |
| [DB] 데이터 모델링(6) - 식별자(Identifier) (0) | 2022.10.24 |
| [DB] 데이터 모델링(5) - 속성(Attribute) (0) | 2022.10.24 |